
В одно время немалой популярностью пользовались так называемые оффлайн-браузеры — программы, позволяющие скачивать на локальный компьютер целые сайты или связанные ссылками определенного уровня вложенности страницы. Возможности оффлайн-браузеров также включали извлечение из веб-страниц контента конкретного типа — изображений, мультимедийных файлов, архивов и так далее, то есть в данном случае программа использовалась как парсер.
Специальное программное обеспечение, предназначенное для автоматизированного сбора публичных данных в интернете по заданным условиям.
Существует множество разных парсеров, реализованных в виде веб-сервисов — SPparser и Q-Parser, десктопных приложений и даже браузерных расширений, например, Parsers, Scraper и Data Scraper для Chrome. Но большинство парсеров обычно затачиваются под выполнение конкретных задач, они не отличаются универсальностью и на деле для решения разных задач приходится использовать разные парсеры. Хотя не все парсеры таковы. Программа Octoparse как раз отличается от других парсеров многозадачностью, но еще большим ее достоинством является гибкость и относительная простота, делающая приложение привлекательным для рядовых пользователей.
Скачать Octoparse можно с сайта разработчика www.octoparse.com/download/windows.
Для работы с программой вам придется пройти процедуру регистрации с подтверждением на электронную почту. После подтверждения вы будете переадресованы на страницу выбора плана. План можно выбрать «Free» и «Premium». Первый план предполагает функциональные ограничения, не слишком значительные, премиальные планы доступны на коммерческой основе с пробным периодом 14 дней. Но перейдем к Octoparse. Что, собственно, умеет эта программа? Извлекать из сайтов данные определенного типа по заданным условиям.
Эти данные — простой текст, гиперссылки, IP-адреса, документы и изображения, адреса электронной почты и номера телефонов, содержимое меню, в том числе меню выпадающие, данные, загруженные с помощью AJAX и JavaScript, исходного кода, отдельных веб-страниц с полной прокруткой, коммерческими редакциями поддерживается извлечение видео. Данные могут быть сохранены в структурированном виде и выбранном формате, так, если это текстовая информация, Octoparse может экспортировать ее в TХT, CVS и HTML, сохранить в облако вашей учетной записи на сайте разработчика.
Парсером поддерживается блокировка рекламы, параллельное выполнение нескольких заданий, просмотр сайтов во встроенном браузере, использование регулярных выражений, настройка cookies и кэша, создание категорий для задач и еще целый ряд дополнительных функций, часть из которых доступна в бесплатной версии приложения.
Пример работы с Octoparse
А теперь рассмотрим работу с «осьминогом» на конкретном примере — извлечении из сайта URL-адресов. Запустив программу, вводим в поля авторизации данные учетной записи пользователя Octoparse и попадаем в интерфейс приложения.
Парсер может работать в двух режимах: в режиме шаблона и в режиме расширенном. Первый позволяет создавать задачи на основе встроенных в программу сценариев, второй предполагает произвольное, а значит и более гибкое конфигурирование парсинга. Нам нужен второй режим, поэтому жмем кнопку «Task» под «Advanced Mode».

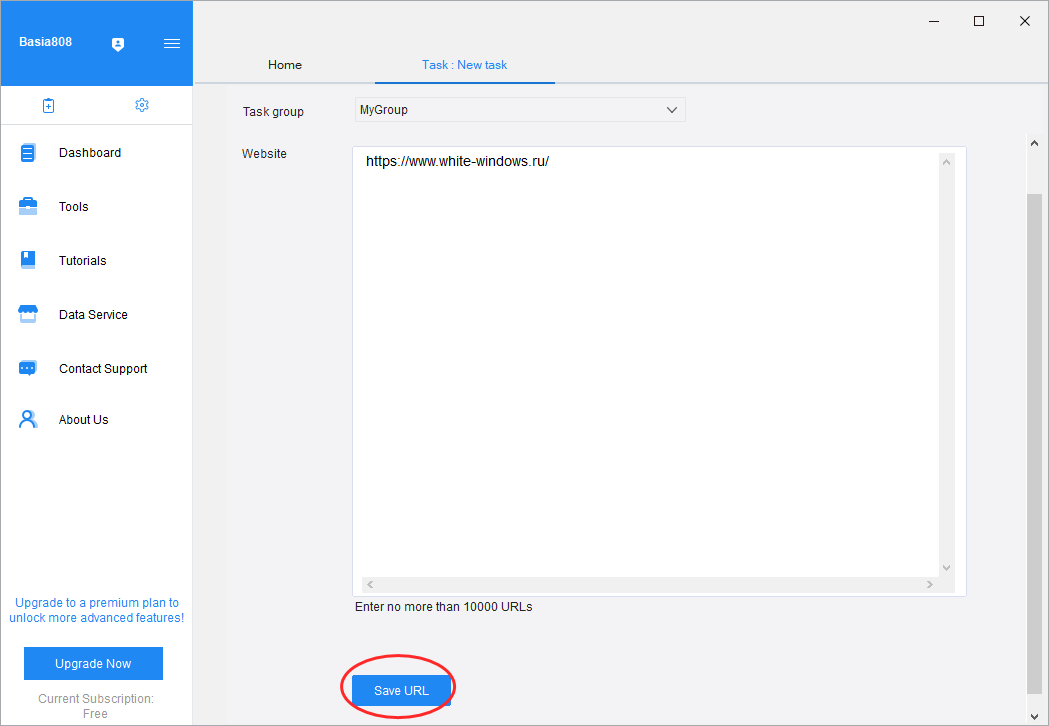
В появившемся поле вставляем адрес сайта или веб-страницы, с которой собираемся работать и жмем кнопку сохранения проекта «Save URL».
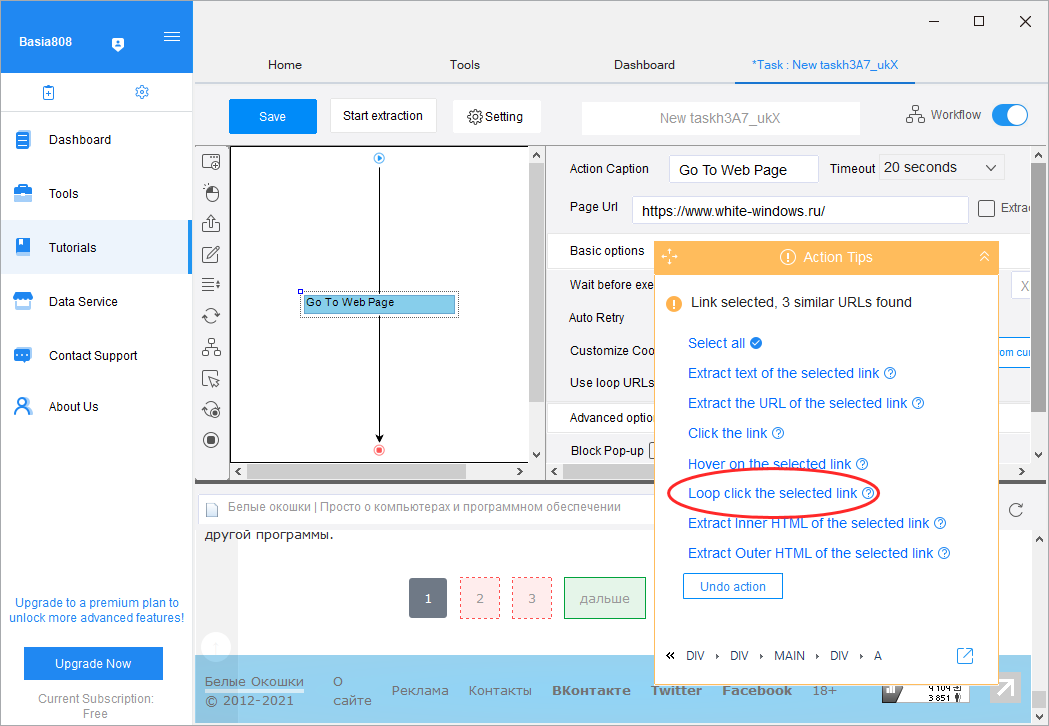
После того как сайт загрузится в окно парсера, создаем цикл перехода по страницам ресурса. Для этого на сканируемом сайте нужно нажать кнопку перехода на следующую страницу, а затем выбрать в плавающем окошке «Loop click the sеlected link». В левой области рабочего окна должен отобразиться созданный цикл.
Следующий шаг — выбор элемента на странице, по которому будет осуществляться отбор. Это может быть прайс, какая-то категория и так далее. После нажатие на интересующий веб-элемент, выбираем в том же плавающем окошке опцию «Sеlect all».
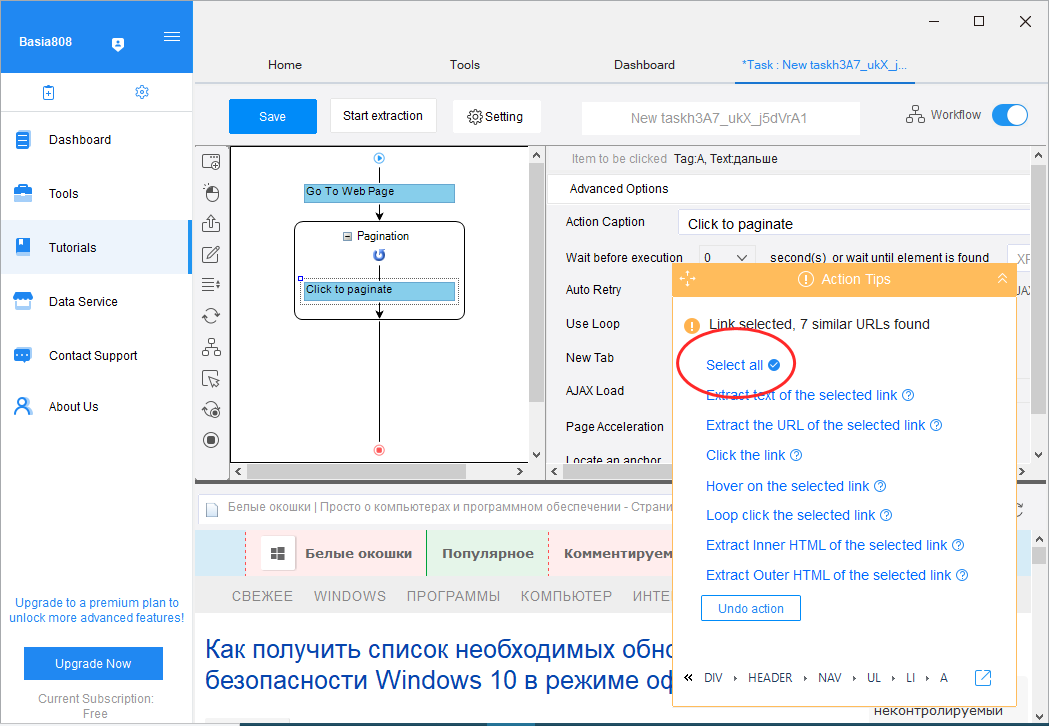
При этом в нижней области плавающего окошка появится нечто вроде таблицы с данными.
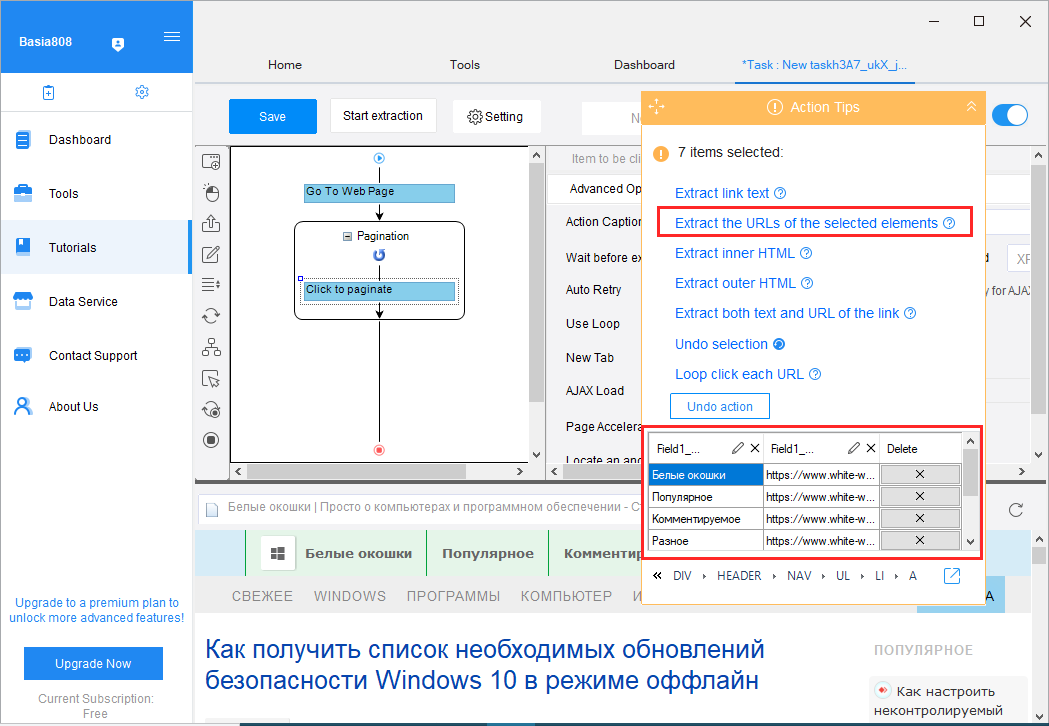
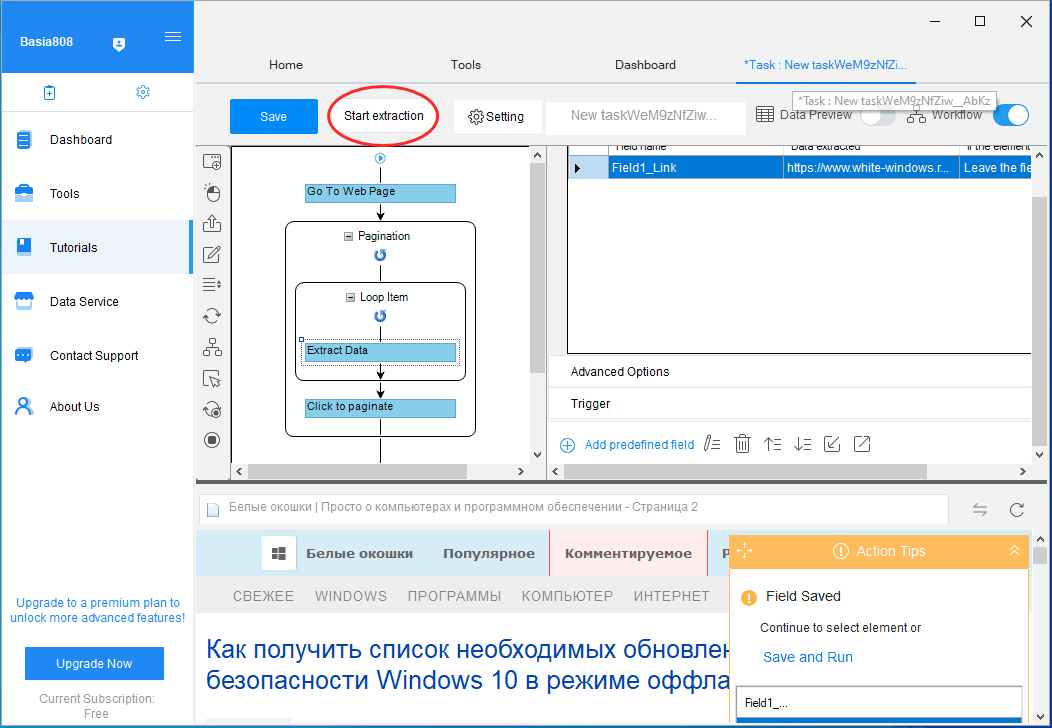
Убедившись, что программа не захватила лишних ссылок (ненужно можно удалить), выбираем в плавающем окошке нужный тип данных, в данном примере «Extract the URLs of the sеlected elements». Всё, теперь можно запускать процедуру извлечения данных нажатием «Start extraction».
Появится окно, в котором вам будет предложено выбрать место сохранения результата. Выбираем «Local extraction», то есть локальный компьютер.
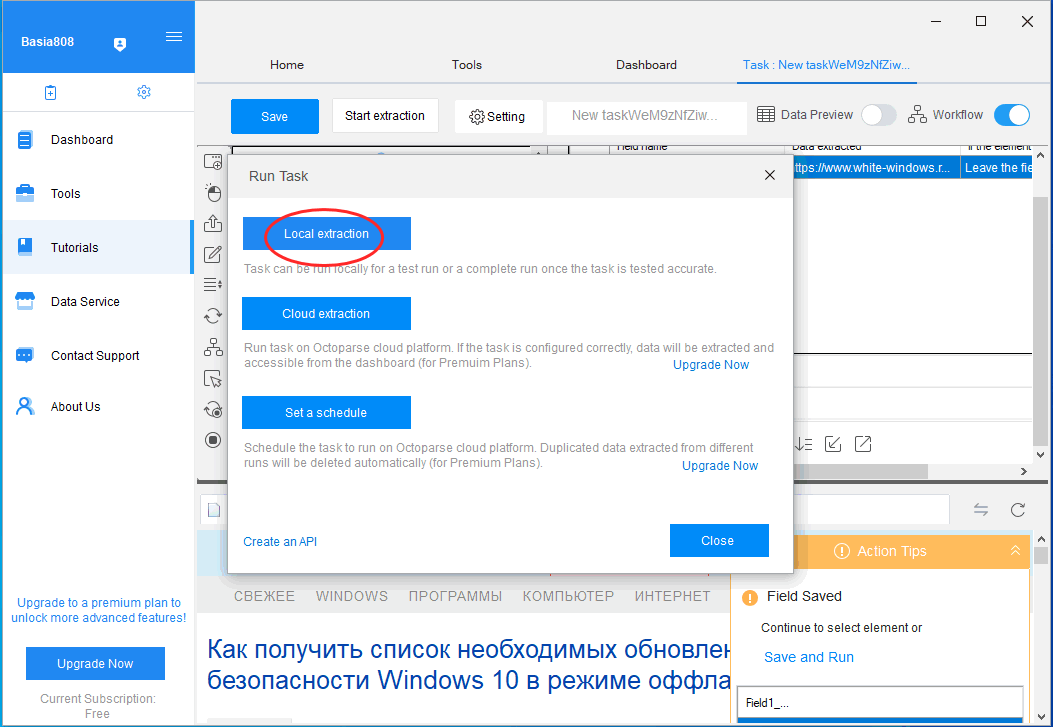
Начнется процедура извлечения информации, которое займет некоторое время, всё зависит от того, задали ли вы выборку данных со страницы, категории или всего сайта целиком.
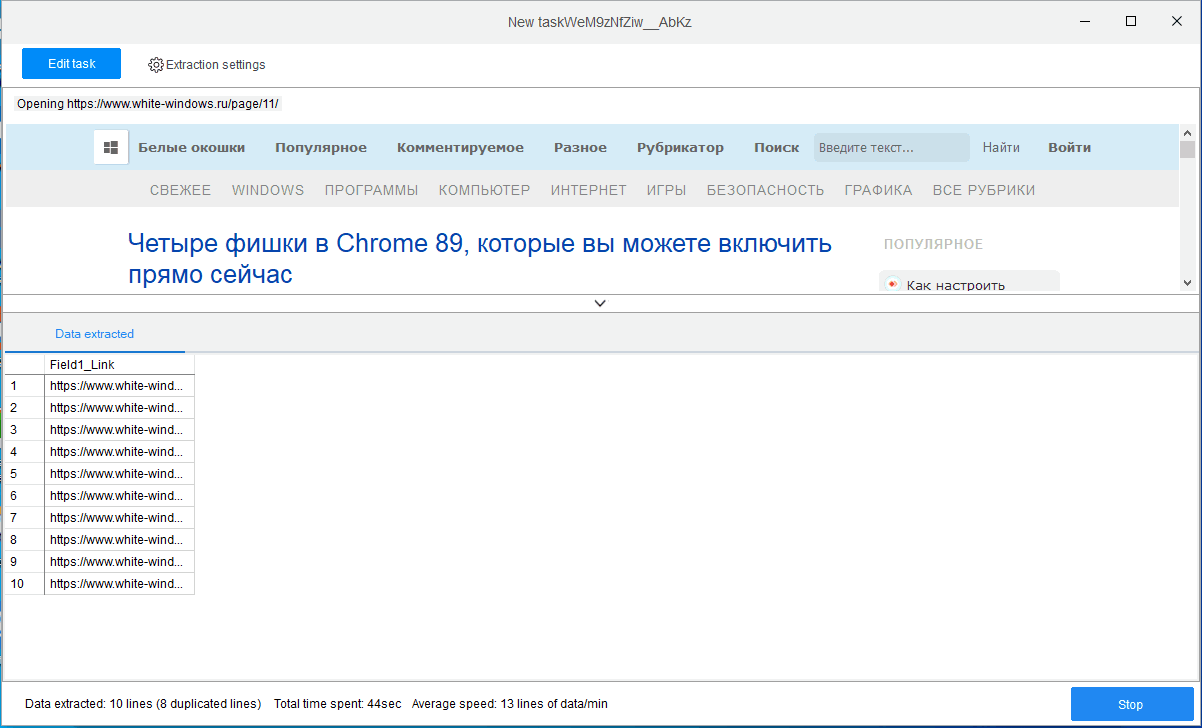
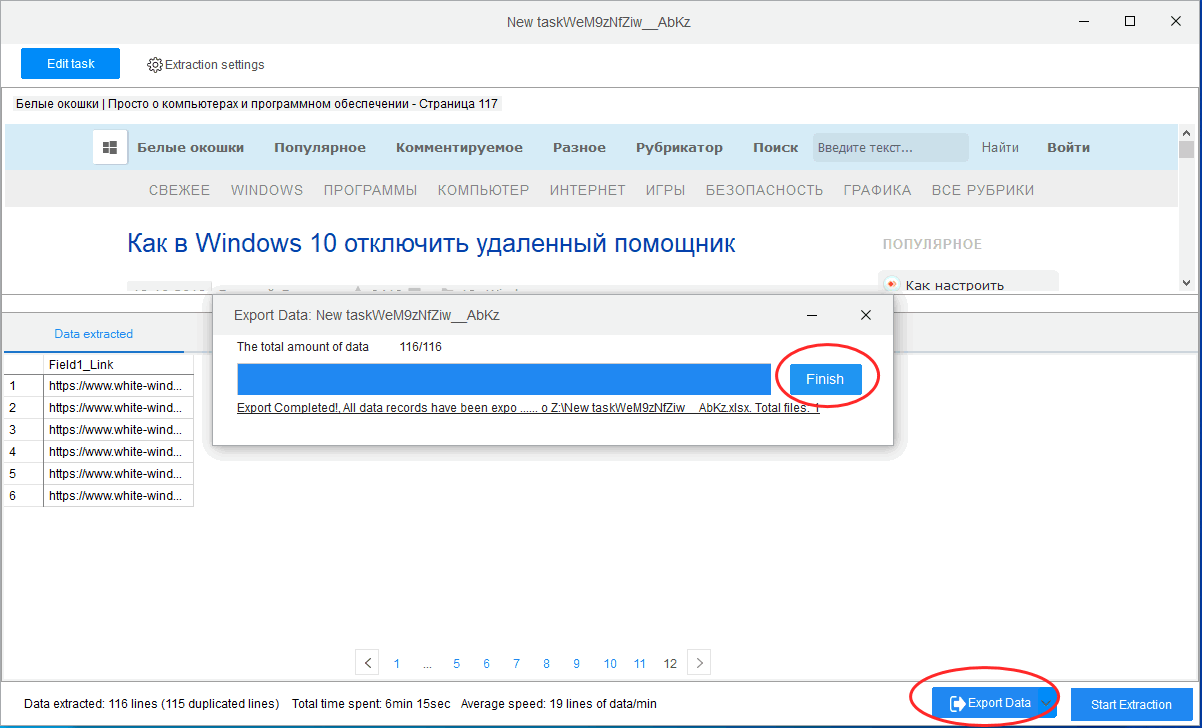
По завершении Octoparse предложит сохранить отчет в файл поддерживаемого формата.
Всё немного сложнее, чем кажется
Хотя Octoparse и ориентирован на широкий круг пользователей, овладеть программой лобовой атакой вряд ли получится. Трудности могут возникнуть при создании циклов и выборе самих данных, поэтому перед тем как приступать к работе с программой, не будет лишним ознакомиться с доступными на сайте разработчика учебными пособиями. Недостатком программы является также отсутствие поддержки русского языка. В общем, если кому-то программа покажется слишком сложной или неудобной, можно начать с чего-то попроще, например, с того же расширения Parsers, которое хотя и уступает на порядок Octoparse, настолько же проще его.

Добавить комментарий